
At Holistic AI, we assess AI models rigorously to ensure they meet security and safety standards. Our latest audit focuses on ChatGPT 4.5, building on insights gained from previous assessments of DeepSeek R1, Grok-3, and Claude 3.7 Sonnet.
Key Takeaways from Our Previous Audits
In our past audits, we identified varying degrees of vulnerability to adversarial attacks across different models:
To assess the models, we conducted a structured evaluation using the following datasets:
The harmful and benign prompts were sourced from a Cornell University dataset designed to rigorously test AI security, drawing from established red-teaming methodologies.
While not a reasoning-based model, GPT 4.5's safety performance compared favorably to the reasoning-based models we’ve tested so far this year. Despite proving susceptible to a single jailbreaking prompt, GPT 4.5's flawless responses to topic-based benign and harmful red teaming prompts resulted in an overall safe response rate of over 99%, higher than the rate observed for Open AI's reasoning-based o1 model.

We also examined the cost efficiency of using ChatGPT 4.5 in comparison with other models. The following chart demonstrates the cost (USD per 1M tokens):
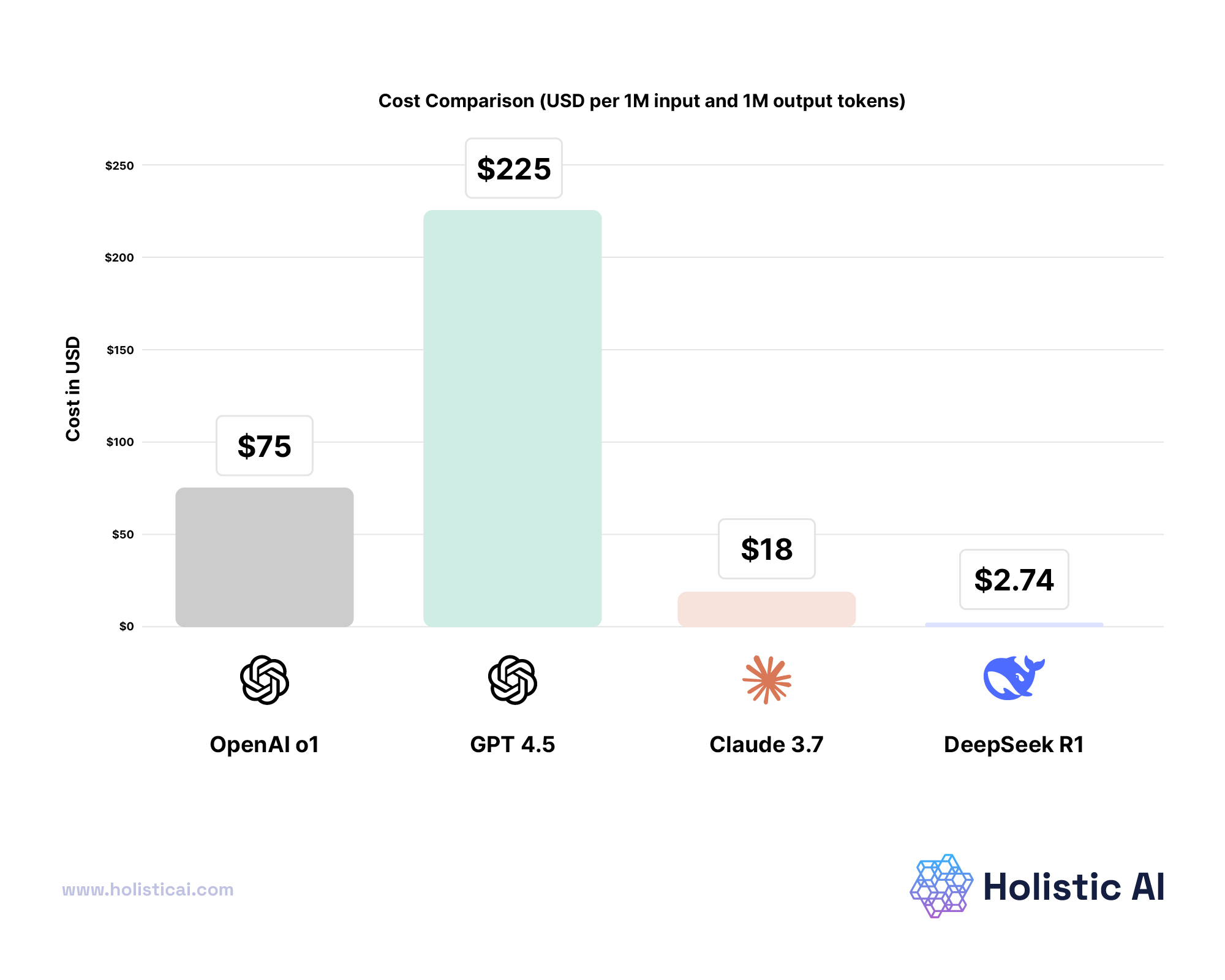
As shown, ChatGPT 4.5 is one of the more expensive options compared to others like DeepSeek R1 and Claude 3.7 Sonnet, which are priced much lower at approximately 2-20 USD per 1M tokens. However, this higher cost assumes superior performance in terms of security and safety. For Holistic AI, we are actively monitoring the usage and spend associated with our ChatGPT 4.5 deployment.
ChatGPT 4.5 stands out for its solid security performance, but, like all AI systems, must remain vigilant in the face of evolving threats. However, for cost-conscious organizations, there are other models that are just as safe available at a lower cost. Our ongoing audits and insights are vital for strengthening AI security across industries. For more information on how to secure your AI deployments, get in touch with Holistic AI today.
The audit used prompts gathered from: https://arxiv.org/abs/2404.01318
DISCLAIMER: This blog article is for informational purposes only. This blog article is not intended to, and does not, provide legal advice or a legal opinion. It is not a do-it-yourself guide to resolving legal issues or handling litigation. This blog article is not a substitute for experienced legal counsel and does not provide legal advice regarding any situation or employer.
Schedule a call with one of our experts


DISCLAIMER: The information provided on this website does not, and is not intended to, constitute legal advice; instead, all information, content, and materials available on this site are for general informational purposes only. Information on this website may not constitute the most up-to-date legal or other information. This website contains links to other third-party websites. Such links are only for the convenience of the reader, user or browser; Holistic AI does not recommend or endorse the contents of the third-party sites.
Readers of this website should contact their attorney to obtain advice with respect to any particular legal matter. No reader, user, or browser of this site should act or refrain from acting on the basis of information on this site without first seeking legal advice from counsel in the relevant jurisdiction. Only your individual attorney can provide assurances that the information contained herein – and your interpretation of it – is applicable or appropriate to your particular situation. Use of, and access to, this website or any of the links or resources contained within the site do not create an attorney-client relationship between the reader, user, or browser and website authors, contributors, contributing law firms, or committee members and their respective employers.
The views expressed at, or through, this site are those of the individual authors writing in their individual capacities only – not those of their respective employers, Holistic AI, or committee/task force as a whole. All liability with respect to actions taken or not taken based on the contents of this site are hereby expressly disclaimed. The content on this posting is provided "as is;" no representations are made that the content is error-free.